








Building out a high performance data science team with extensive data literacy skills is a hefty investment. And many businesses struggle to find and develop seasoned data science talent.
Why? The competition for top analytical talent is high and retention of that talent has become very difficult and expensive – even for house-hold brands.
As technology advances at lightning speed and data continues to pile up, it’s clear that a new approach is needed to hiring and building data science teams.
What Does a Data Scientist Do?
Data scientists are big data wranglers; they gather and analyze large sets of structured and unstructured data. A data scientist’s role combines computer science, statistics, and mathematics. Their job is to analyze, process, and model data then interpret the results to create actionable plans for companies and other organizations.
A data scientist often balances both technical skill sets and communication skills. In business settings, data scientists not only need to make sense of a lot of messy data (i.e. all the different sources and formats they’re in), they need to communicate complex ideas to help others in the business make smart, data-driven decisions.
Harvard Business Review coined “Data Scientists” as “the sexiest job of the 21st century”.
They wrote:
“If ‘sexy’ means having rare qualities that are much in demand, data scientists are already there. They are difficult and expensive to hire and, given the very competitive market for their services, difficult to retain.”
Why is the Demand so High for Data Scientists?
Businesses have a plethora of data. Millions of data pours into them, every day, from hundreds of sources. And that amount has been increasing over the years, a phenomenon largely driven by the success of large tech companies collecting it.
As technology advances, the ability to collect all that data has scaled and become more economical. Which means that, across all industries, there is an insane amount of data waiting to be analyzed.
The problem is that there is a major shortage of skills to handle the increasing demand to make sense of all that data. McKinsey predicted the U.S. would experience a shortage of 250,000 data scientists by 2024.
In fact, the demand is so high that even individuals who have pursued computer science and technical programs at universities are being thrust into performing demanding data analytic positions in the workplace.
The Average Cost of a Data Science Team
Coupled with this challenge of overall scarcity of experts is the high salary expectations.
According to the U.S. Bureau of Labor Statistics, the average salary for a data scientist working in the U.S. is $195, 000. Behind this price tag is low supply, high demand, and the skill sets associated with the role.
.png)
Of course, these numbers depend on a few factors:
- Geography
- Technical skills
- Organization sizes
- Industry
- Education
We wanted to see what the cost/benefit analysis looked like for a Data Scientist. So our team broke it down.
Obviously AI Cost/Benefit Calculator
We created a cost/benefit analysis (below) to help show the difference between the traditional machine learning route and no-code machine learning. We find it helpful to refer to when people ask us about the value of no-code tools.
In it, we take the annual salaries of a Data Scientist, a DevOps Engineer, and a Software Engineer and break down their cost per day and how long it takes to complete tasks that are typical of building machine learning models.
For this breakdown, let’s assume the following.
Inputs:
- Rows of Data: 100,000
- Data Sources: 1
- Number of Models to Build: 1
- Number of Data Scientists: 1
- Number of DevOps engineers: 1
- Number of Software Engineers: 1
Our next assumption is around annual salaries (in USD):
- Data Scientist Annual Salary: $200,000
- DevOps Annual Salary: $120,000
- Software Engineer Annual Salary: $120,000
All of these numbers are based on the average salary, pulled from the U.S. Bureau of Labor Statistics.
Finally, we have what each of these roles makes in a day as well as the number of work days in a US calendar. We got these numbers by averaging the number of hours worked in the US per year (2080 hours):
- Number of workdays in a year (US): 260
- Data Scientist salary per day: $769
- DevOps salary per day: $462
- Software engineer salary per day: $462
Assuming all of the above, we break down 6 routine tasks to show how many days it takes to complete and what their cost is.
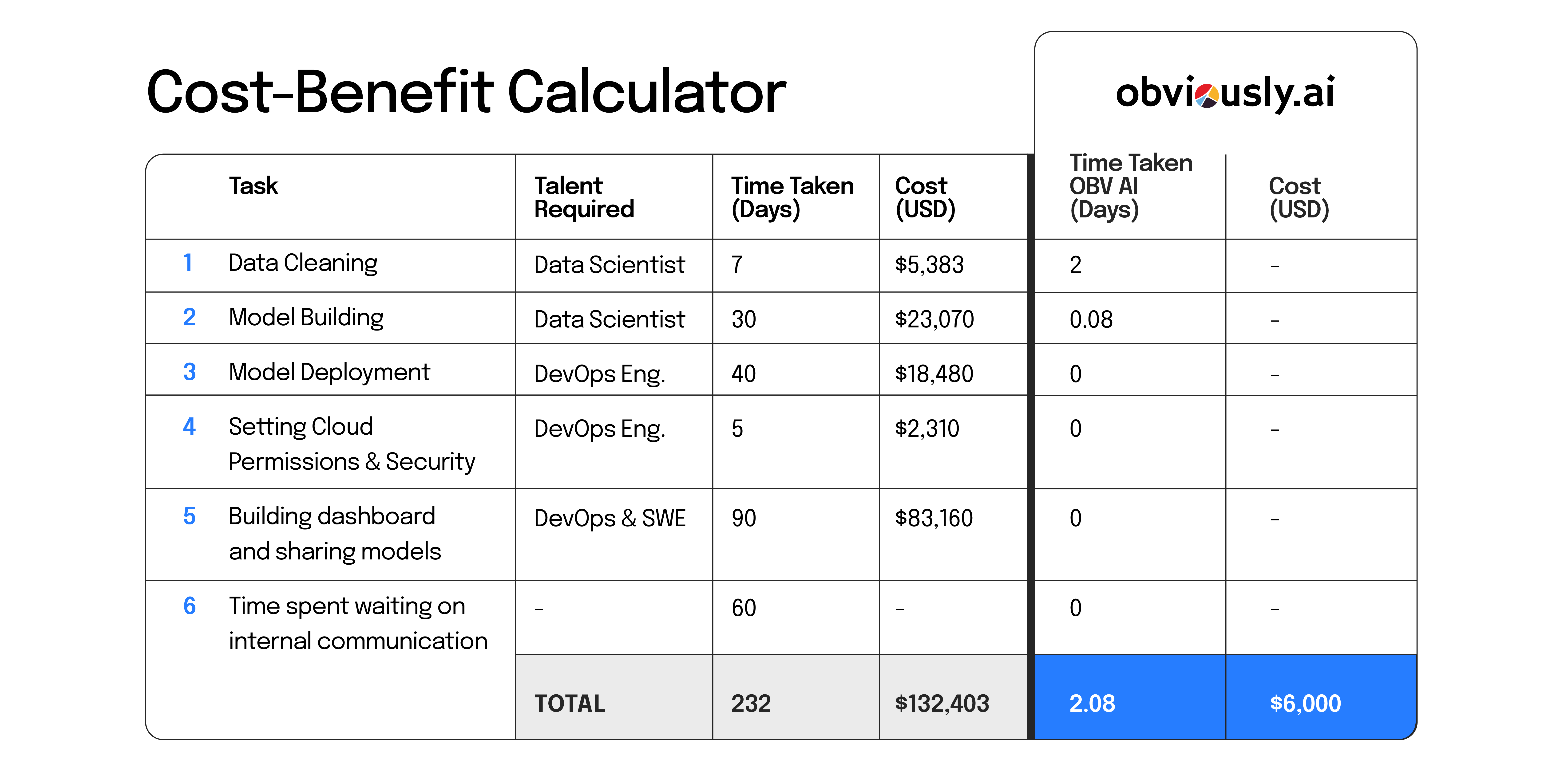
For instance, let’s look at what it takes to clean data, one of the simplest and shortest tasks on our list.
Data cleaning/data preparation is one the most important parts of machine learning. Any data scientist will tell you that the majority of their time is spent on cleaning, rather than machine learning.
Data Cleaning: Time for Data Scientist
The talent required for this task is a Data Scientist. In total, it takes 7 days to complete and costs just over $5,000.
Taking seven days to clean data makes sense—this task is a lot of manual work. If businesses want a data driven culture and make air tight predictions, they need properly formatted and structured data.
But data cleaning often looks like:
- Fixing spelling and syntax errors
- Standardizing data sets
- Correcting mistakes such as empty fields
- Identifying duplicate data points
- Normalizing data
- Imputing additional data
- Adding business logic
That’s a lot of tedious work. But remember: Models run best on structured data, which takes time to clean through. Having a large enough dataset is essential to creating an effective model. However, more data means more computing power and time required to execute the project.
Data Cleaning: Time in Obviously AI
In Obviously AI, data cleaning only takes 2 days.
We take an industry standard approach to our data cleaning, which involves:
- Standardization - Checks for standardization within your columns
- Class balancing - Ensures your features and classes aren't skewed or biased
- Data sensitivity - Checks how sensitive your data is to external changes
- Outlier recognition - Checks for outliers and their likely impact on the model
- Statistical checks - Checks for P-values, sparseness, variance, etc. in your data
- Business logic - Ensures your data correctly represents your KPIs
- Data merging - Combines data from different datasets
- Data enrichment - Creates new columns
The time your team gets back means you can make predictions and come to business decisions faster. Not to mention, your data scientists get more time back to conduct high-value tasks, such as aligning with executives on strategies business decisions.
Model Building: Time for Data Scientist
Let’s take a look at another routine task: Building a machine learning model.
Machine learning assists with data analysis and bettering workflows. The quicker that models are deployed, the better—the ability to make more informed business decisions falls short if a model can’t deliver fast and accurate results from the data.
If companies aren’t able to deploy models inline with emerging business operations, it’s not cost effective to deploy machine learning models.
The talent required for this task is a Data Scientist. In total, it takes them around 30 days to build a machine learning model, and costs just over $23,000.
However, according to Algorithmia’s “2020 State of Enterprise Machine Learning”, 50% of respondents said it took 8–90 days to deploy one model, with only 14% saying they could deploy in less than a week.
Model Building: Time in Obviously AI
Now, compare that 30 days and $23,070 to the time and cost for Obviously AI.
In our platform, an accurate and efficient machine learning model is built in seconds. In those seconds, there’s a lot going on behind the scenes.
During this time, Obviously AI is running the dataset through final pre-processing stages and is training multiple models. The backend will run various hyperparameter combinations of top performing algorithms. This essentially means trying multiple algorithms with different settings, mixing and matching them resulting in 10000+ of algorithms running simultaneously, to find the one that performs the best.
From 30 days to a matter of seconds, data scientists (and anyone, really, since no-code tools democratize the power of predictive analytics) have a trained model ready to generate prediction reports in a fraction of the time it would take if built using traditional code.
Solving the Supply and Demand Problem of Data Scientists
The reality is that no one, or even two, Data Scientists can cover all the bases. And they shouldn’t be expected to. But the advance of big data shows no signs of slowing. If companies sit out on maximizing on their data due to a lack of talent, they risk falling behind as competitors gain nearly unassailable advantages.
This puts tremendous pressure on data scientists.
The long-term solution to solving the supply problem of data scientists is to democratize all that knowledge. Businesses need to enable more people without data backgrounds to apply complex machine learning.
Some businesses are turning towards courses that help employees reskill. Others are hiring for roles like “data translators,” which aim to bridge the gap between business users and data scientists.
Those that are serious about solving the problem? They’re actively implementing tools that simplify the machine learning process.
Data scientists must help businesses navigate a world of global data collection and applications. Their role is vital to the success of the organization. Tools like no-code machine learning empower entire teams with data and decision-making, regardless of their technical skillset.
When that power is democratized, businesses see a reduction of bottlenecks, an increase in intelligent decision-making, and data scientists have more time to work on strategic projects that propel the business forward.
Summary
No-code machine learning tools don’t replace a data scientist. Rather, they mimic a data scientist such that even a non-technical individual could perform data analytics with just a few lines of code or a few clicks. These tools free up time, speed up processes, and empower entire teams to harness the power of machine learning.






